
3. 伺服器運作原理
現代的網站系統架構圖最簡單的畫法就是C-S圖:
flowchart LR C[Client] --> S[Server]
第一章我們了解了C-S中間的那條線 – HTTP協定,第二章我們了解了Clinet也就是瀏覽器,接著就來完善這個C-S圖的最後一塊拼圖!
很多人以為伺服器是外星科技,但其實伺服器本質上就是一台「不關機、沒有螢幕、效能很強的電腦」。
它一樣有 CPU、記憶體(RAM)、硬碟(SSD),作業系統通常是穩定且有效率的 Linux(如 Ubuntu, CentOS)。
它之所以叫伺服器,是因為它運作著專門「提供服務(Serve)」的軟體,並且擁有固定的公有 IP,維持 24 小時開機,隨時等待世界各地的請求。
既然伺服器只是一台性能很強的電腦,那當它收到我們從遠端跨越大海傳來的 Request 時,它是怎麼處理的?
在最經典的現代網站架構中,Server 的內部其實並不是鐵板一塊,而是由三個各司其職的軟體層級組成的,這在資訊工程中被稱為「三層架構(3-Tier Architecture)」:
flowchart TD
C[Client 瀏覽器] --> WS[Web Server 網頁伺服器]
WS --> AS[Application Server 應用程式伺服器]
AS --> DB[(Database 資料庫)]為了好理解,我們可以把整台伺服器想像成一家「銀行總行」,當 Request 進門後,會依序穿過以下三個辦公室:
1. 門衛與行政前台:網頁伺服器(Web Server)
像是Nginx、Apache等軟體,是銀行的「前台抽號碼牌行員與保全」。它站在網際網路的最前線接待客戶。主要工作不是動腦算數學,而是維護安全、管理排隊連線(反向代理),以及處理最簡單的請求。
如果客戶只是要看貓咪圖片、網頁排版樣式這種 靜態內容 Static Content ,前台行員轉身就能從身後的硬碟櫃(SSD)直接拿給客戶,不需要驚動後面的大老闆。這能極大地節省系統資源。
2. 核心大腦:應用程式伺服器(Application Server)
常見的網頁技術引擎如Node.js (Express)、Python (Flask)、Java (Spring Boot)、Next.js Server就像是辦公室裡默默坐著的「貸款審查主管」。
當前台行員發現客人的請求需要「動腦筋」(例如:想查 Harry 的期末成績、驗證登入密碼、計算購物車折扣等 Dynamic Content 動態內容),就會把表單送進這間辦公室。
這一層運行著你寫的後端程式碼。它負責跑邏輯、算數學、驗證你的身份(Cookie/Session),並決定接下來要向倉庫調用哪些資料。
3. 數據倉庫:資料庫管理系統(Database)
我們熟知的 PostgreSQL、MySQL、MongoDB,銀行後方的「地下保險庫與機密檔案室」。它負責安全、有條理地儲存所有珍貴數據。當大腦(Application Server)傳來查詢指令時,資料庫會用極快的速度在硬碟中翻找出 Harry 的成績欄位,再遞回給大腦。
伺服器如何處理「成千上萬的連線」?
這是資管與資工在架構設計上最常考的痛點:如果同一秒鐘有 10 萬人都要看貓咪圖片,伺服器怎麼辦?
不同的後端技術,處理併發(Concurrency)連線的哲學完全不同。舉個例子 : 「餐廳點餐」
1. 多執行緒模型 Multi-Threading
傳統的 Java / Python 哲學,伺服器每收到一個請求,就派一個專屬的員工(執行緒 Thread)去全程伺候這個客人。
像是那種一個服務生只服務一桌客人的高級西餐廳。客人看菜單(等待網路傳輸或資料庫讀取)時,服務生就在旁邊罰站。
雖然邏輯直覺清晰,但如果客人暴增,伺服器就得雇用大量員工,記憶體(RAM)很快就會被吃光、導致伺服器癱瘓。
2. 事件驅動非同步 I/O(Event-Driven / Async)
現代的 Node.js (V8) 哲學,全公司只有一個員工(單執行緒 Single Thread),配合一個「事件輪詢(Event Loop)」機制。
- 餐廳比喻: 現代美食街或麥當勞。
- 櫃檯結帳人員(單執行緒)負責瘋狂幫客人點餐(接收 Request)。
- 點完餐發給客人一張號碼牌,就把任務丟給廚房(作業系統底層核心或執行緒池去處理撈資料庫等雜事)。
- 櫃檯人員不停下來等,立刻幫下一個客人點餐。
- 當廚房做好了(資料讀取完畢),會按鈴通知(觸發 Callback 事件),櫃檯人員再抽空把餐點交給對應號碼牌的客人(回傳 Response)。
記憶體消耗極低,單台伺服器就能同時支撐海量的輕量級請求(例如聊天室、API 網關)。但缺點是如果遇到需要大量 CPU 算數學的任務(如影片轉檔),那個唯一的櫃檯人員就會被卡死,後面的客人都沒辦法點餐。
伺服器崩潰
Q:在每年的雙十一購物節、或是大學選課系統開放的瞬間,伺服器常常會因為瞬間湧入的幾十萬個 Request 而崩潰(俗稱網站掛了)。請試著從伺服器運作原理中的「CPU、記憶體、硬體與併發模型」出發,思考伺服器在崩潰前,內部可能遭遇了什麼瓶頸?
- 答案引導建議:
- 記憶體耗盡(OOM, Out of Memory): 如果採用傳統多執行緒模型,為了處理太多連線,系統瘋狂建立 Thread,導致記憶體被塞滿,作業系統為了自我保護而強制關閉伺服器。
- 資料庫連線池枯竭(Database Connection Pool Exhaustion): 所有的 Request 都卡在大腦(應用層)等待資料庫回應,資料庫在瞬間無法處理這麼多精準的讀寫指令,導致整條流水線大塞車。
- 頻寬被吃滿: 伺服器的網路卡出口就像水管,當回傳的資料(如圖片)總體積超過了伺服器機房的頻寬上限,封包開始瘋狂丟失。
CDN
Content Delivery Network,內容傳遞網路,一組分布在世界各地的伺服器群組(或稱邊緣伺服器,Edge Servers),透過「地理位置就近發配」與「快取(Cache)」技術,加速網頁的讀取速度,並減輕源頭伺服器的負擔。
- Web Server 是資料的「生產工廠(源頭)」。
- CDN 則是開在使用者家門口的「便利商店(全台/全球連鎖分店)」。
- 靜態資源外包給 CDN:我們把網站上幾個月都不會變的「死資料」(如:學校 Logo 圖片、前端 JS 打包檔、CSS 排版檔),複製幾萬份發配給全球各地的 CDN 節點(便利商店)。當你想看貓咪圖片時,離你最近的台灣 CDN 節點會直接回傳(Static Content)給你,封包不用跨越大海去美國總店。
- Web Server 專注動態運算:90% 的靜態流量在 CDN 就被攔截並解決了。真正會敲響 Web Server 大門的,只剩下那些需要大腦(Application Server)進資料庫撈取、因人而異、即時變動的動態資料(Dynamic Content)。
分散式快取
雖然變動的資料庫數據(如:商品庫存、熱門看板文章、使用者登入狀態)屬於動態內容(Dynamic Content),CDN 幫不上忙;但如果在一秒內有 10 萬人同時點進同一個熱門商品頁面,核心大腦就必須向資料庫轟炸 10 萬次一模一樣的 SQL 指令。
資料庫讀寫硬碟的速度非常慢,承受不住這種瞬間暴增的重壓,網站依然會崩潰。為了解決這最後一哩路的瓶頸,現代架構在「大腦」與「倉庫」之間,安插了一個極速的中繼站——分散式快取(Distributed Cache)。
分散式快取(如 Redis)是一種完全運行在「記憶體(RAM)」中的高效能資料儲存系統。是獨立架設在外的快取伺服器叢集(Cluster)
像圖書館櫃台工讀生桌上的便利貼,把經常被問的問題、書籍的資料都寫上去,當有人來詢問時,喵一眼便利貼就能解答了。分散式快取便是把這種短時間(3~4個月)不會變動的動態資料,暫存到速度極快的記憶體中,避免大腦每次都大費周章地跑去倉庫(資料庫)翻箱倒櫃。
分散式
Q: 那我為什麼不要把快取直接寫在 Application Server 自己的記憶體(Local Cache)裡不就好了嗎?
答案是因為在現代 Next.js 或大型微服務架構中,為了應付幾十萬人,我們通常會同時開 5 台、甚至 10 台 Application Server。
如果用 Local Cache,A 伺服器幫 Harry 算的成績,B 伺服器根本不知道;當使用者的下一次請求被分流到 B 伺服器時,B 又得去轟炸一次資料庫。
若使用分散式快取,則不管前面有幾百台 Application Server,大家都共用同一張巨大的便利貼辦公桌。A 伺服器撈完資料寫進 Redis,B 伺服器下一秒就能直接共享成果 !
小結
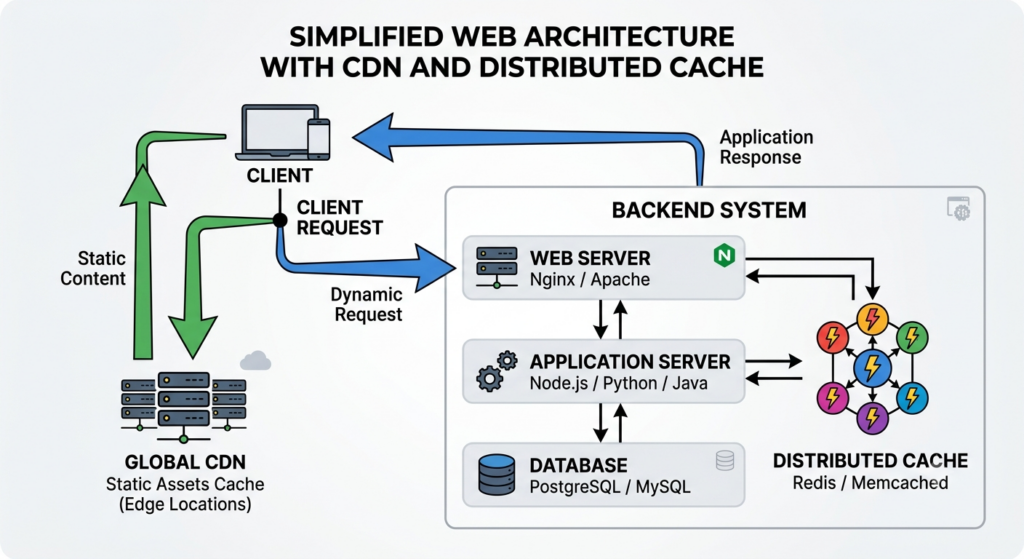
了解了整個C-S架構,接下來就可以正式進入資安領域啦! 會要先講C-S架構是因為常見的駭客攻擊主要都是針對這三者(Clint, 應用層, Server),接著就從客戶端開始 !