
2. 瀏覽器的運作原理
前面了解了網際網路的運作原理後,接著我們來聊聊瀏覽器!
當我們在前面的章節學到了 IP 地址、DNS 查榜、以及 HTTP/HTTPS 的特務交握後,瀏覽器終於成功從伺服器那裡拿到了回應主體(Response Body)——也就是一堆由 HTML、CSS 和 JavaScript 組成的原始碼文字。
但是,人類沒辦法直接閱讀 <div>、p { color: red } 這種程式碼。瀏覽器(Browser)的核心任務,就是將這些枯燥的程式碼,翻譯成我們眼睛看得到的精美網頁。 這個將原始碼轉換為畫面的過程,在電腦科學中被稱為「渲染流程(Rendering Process)」。
瀏覽器的兩大核心
在深入流程前,我們要先認識瀏覽器內部的兩個最重要的大腦:
- 渲染引擎(Rendering Engine): 負責看 HTML 和 CSS,把網頁的骨架與皮肉畫出來(例如 Chrome 的 Blink、Safari 的 WebKit)。
- JavaScript 引擎: 負責解讀 JS 程式碼,處理網頁的動態特效與邏輯(例如 Chrome 的 V8)。
渲染
當瀏覽器拿到 HTML、CSS 檔案後,渲染引擎會像工廠流水線一樣,進行以下五個步驟:
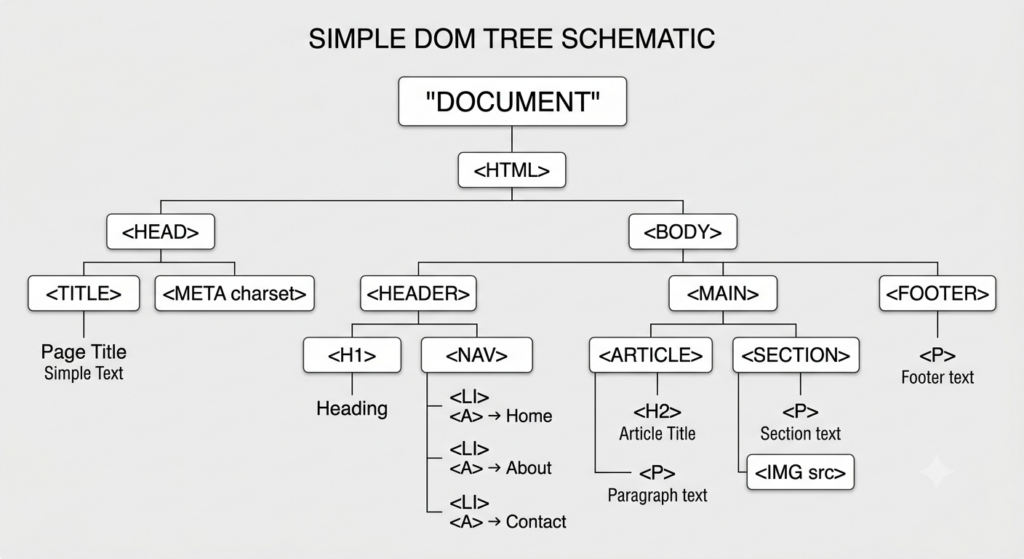
第一步:構建 DOM 樹 (DOM Tree)
瀏覽器從上到下閱讀 HTML 原始碼。當它看到 <html>、<body>、<div>、<img> 等標籤時,會把它們轉換成一個像家族樹狀圖一樣的結構,叫做 DOM 樹(Document Object Model Tree)。
- 白話來說:這一步決定了網頁上有哪些「成員」(這裡有一段文字、那裡有一張圖片)。
第二步:構建 CSSOM 樹 (CSSOM Tree)
在讀取 HTML 的同時,瀏覽器如果讀到了 CSS 樣式表,它會另外築起一棵樹,叫做 CSSOM 樹(CSS Object Model Tree)。
- 白話來說:這一步決定了成員們該穿什麼衣服(這段文字是 16px 且是藍色的、那個區塊要有藍色背景)。
第三步:打造渲染樹 (Render Tree)
有了骨架(DOM)和衣服(CSSOM),瀏覽器會把這兩棵樹合併在一起,生成 渲染樹(Render Tree)。
- 關鍵細節: 渲染樹非常聰明,它只保留真正需要顯示在畫面上的東西。如果某個標籤被 CSS 設定了
display: none;(隱藏),它雖然存在於 DOM 樹,但會被渲染樹剔除,因為它不需要被畫出來。
第四步:版面配置 (Layout / Reflow)
有了要顯示的成員與樣式後,瀏覽器要開始拿著量尺,計算每個人在螢幕上的精確幾何位置與大小。
- 它會根據螢幕解析度(手機還是桌機),去計算「這個區塊的寬度是多少像素」、「圖片要靠左還是靠右」。
第五步:著色上漆 — 繪製 (Paint)
最後一步!瀏覽器把計算好的幾何區塊,真正轉換成螢幕上的像素點,把顏色、陰影、邊框、圖片像素「畫」到螢幕上。這時候,使用者才能真正看到網頁。
JS 引擎
有學過html都知道,老師總是會說<script>要寫在最下面,為什麼?
因為渲染引擎如果讀到<script>會立刻停下所有的手上工作(暫停解析 HTML),把主導權交給 JavaScript 引擎。JS引擎會將JS編譯成CPU看得懂的電腦語言,編譯完成後瀏覽器會開始下載JS檔案並執行。直到這些流程都結束後,渲染引擎才能繼續回頭蓋它的 DOM 樹。
那為什麼一定要在使用者的瀏覽器中下載JS?
因為 JavaScript 是一門「客戶端腳本語言(Client-side Scripting Language)」。 網頁的互動(例如:點擊按鈕跳出視窗、購物車金額即時計算)必須即時反應。如果每次滑鼠動一下,都要發送 request 回去大洋彼岸的伺服器計算、再回傳 response,網頁就會卡頓到無法使用。 因此,必須把 JS 檔案下載到使用者的電腦上,利用使用者自己的 CPU(透過 JS 引擎)來跑這些互動邏輯。
小結
瀏覽器做的事情其實比較簡單,沒什麼太複雜的操作,真正難題在,前端架構們要如何讓自己的架構能夠最快完成這一切,讓使用者看到畫面並開始使用呢? 那就是前端工程師要處理的問題了。(總不可能讓使用者在電腦面前看空白畫面5分鐘,現代人10秒鐘的耐心都沒有)