
1. 在LLM之前
以下內容是我根據Recurrent Neural Networks (RNNs): A gentle Introduction and Overview這篇論文的讀後重點整理 https://arxiv.org/pdf/1912.05911
在了解Agent之前我們需要先來了解什麼是LLM,但是了解L L M是什麼之前,我們必須先要了解什麼是神經網路!
以下內文圖片皆出自於Recurrent Neural Networks (RNNs): A gentle Introduction and Overview這篇論文
一般神經網路與時序資料的挑戰
神經網路分為兩種,一種是早期的神經網路( DNN),另外一種是較現代的遞迴神經網路( R N N)。
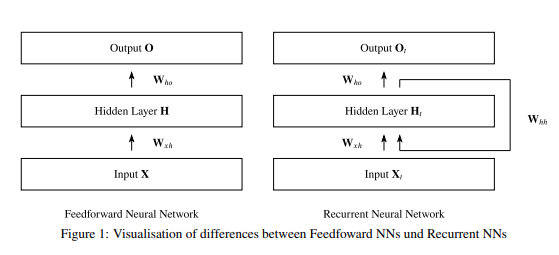
一般神經網路的資料只能單向往前傳,每一筆輸入彼此獨立,互不相干。
適合處理靜態、獨立的資料——比如一張照片、一筆房屋特徵,輸入進去,輸出結果,中間不需要記住前面發生過什麼。
問題出在時序資料。語言、語音、股價這類東西,前後有關聯,長度也不固定。一般 DNN 沒有記憶機制,讀完這個字就忘了上一個字,自然沒辦法處理這種「有順序、有上下文」的資料。這也是後來 RNN 登場的原因。
循環神經網路 (RNN)
RNN 的核心想法很直覺:資料不要一次全部塞進去,而是像讀書一樣,一個時間步、一個時間步依序讀入。文字從左到右、語音從前到後,有先後順序的序列資料,就是為這種架構設計的。
網路裡有一個叫隱藏狀態(Hidden State)的東西,你可以把它想成模型的短期記憶。每走到一個時間步,它會把「現在讀到的輸入」和「上一步留下來的記憶」合在一起,更新成新的狀態,這樣上下文就不會立刻消失。
實務上,模型通常會先經過預訓練(Pre-training):在真正派上用場之前,利用海量的巨量資料讓它進行大規模的學習與調整。
這個過程主要結合了兩個核心步驟:首先是正向傳播(Forward Propagation),資料由輸入層進入,一層層向後計算出預測結果與誤差損失;接著觸發反向傳播(Backpropagation),利用微積分的連鎖律(Chain Rule),將誤差從輸出層逆向傳回網路中,藉此計算出各層的梯度,並精準調整每一組權重與偏差(Bias)。來回反覆幾輪之後,模型才漸漸摸索出預測的規律。
訓練時主要靠三組權重:處理輸入的、負責記憶在時間步之間傳遞的,以及把隱藏狀態接到輸出的。重點是,不管序列有多長,各時間步共用同一套權重,這也是 RNN 能處理任意長度序列的關鍵。
不過 RNN 並非完美。時間軸上權重反覆相乘,序列一拉長,就容易出現梯度消失或梯度爆炸——模型要嘛忘光遠處的資訊,要嘛數值炸掉,長期記憶始終是個硬傷。

解決失憶問題—LSTM 與 DRNN
為了對付 RNN 的失憶症,LSTM(長短期記憶網路)在內部加了一條細胞狀態(Cell State),像一條長期記憶的傳送帶。它還有三道門——遺忘門、輸入門、輸出門—決定哪些舊資訊該丟、哪些新資訊該留。記憶的更新改用加法而不是一路相乘,梯度比較能沿著時間軸傳回去,長序列上的遺忘問題因此大幅改善。
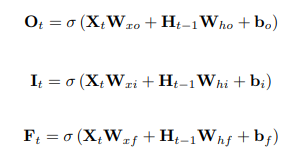
除了 LSTM,也有人從「堆深度」和「拉長視野」兩個方向改 RNN。
Deep RNN(深度循環神經網路)像疊鬆餅,把多層 RNN 疊在一起。底層抓字面、低階特徵,越往上越能抽象出語意。
Dilated RNN(膨脹循環神經網路)則用跳躍連線,每隔幾個時間步才做一次記憶連結,等於在時間軸上跨步傳遞資訊。路徑變短,長距離特徵比較抓得到,計算上也比較有並行的空間。
捕捉全局特徵—BRNN
標準 RNN 只能單向讀——從過去到現在,看不到後面。但理解一句話,有時候得先知道後面講什麼,回頭才看得懂前面。雙向循環神經網路(BRNN)就是在同一層裡開兩條軌道:正向 RNN 從句頭讀到句尾,逆向 RNN 從句尾倒著讀回句頭。
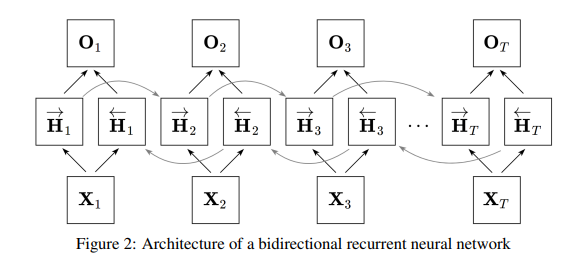
每個時間步,模型會把兩邊的隱藏狀態拼接(Concatenate)起來,變成一個同時帶有「前面上下文」和「後面上下文」的特徵向量。做語言理解、機器翻譯或語音辨識時,這種全局視角很有幫助,不容易因為只單向閱讀而漏掉關鍵線索。
代價是,逆向那條路必須等整句話讀完才能開始算,所以 BRNN 不適合需要邊聽邊說的即時場景,也沒辦法直接拿來做純文字生成——那類任務還是得靠單向模型。
Seq2seq 與 Transformer 的演進
很多任務的輸入和輸出長度不一樣,比如中翻英、文章摘要。

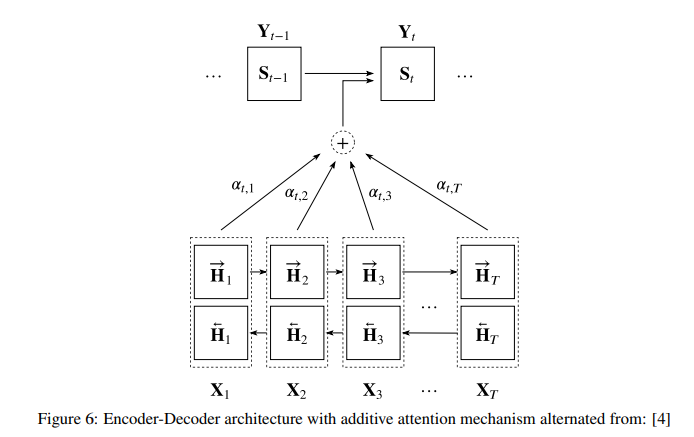
Seq2seq(序列到序列)引進了 Encoder–Decoder(編碼器-解碼器) 架構來處理:Encoder 負責吃進整段輸入,並將其壓縮、提煉成一個固定長度的語意向量(Context Vector);而 Decoder 則接手這個向量作為初始線索,開始進行文字接龍,逐步生成目標輸出。
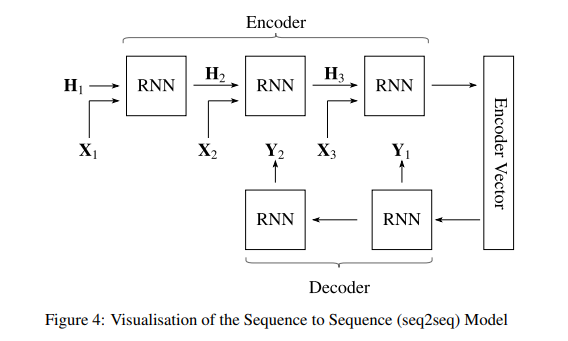
但固定長度的向量很快就變成資訊瓶頸——句子一長,前面的內容容易被擠掉。注意力機制(Attention)解決了這件事:Decoder 每生成一個字,都可以回頭對齊 Encoder 在各個時間步的隱藏狀態,需要哪段就「看」哪段,長文本的品質因此明顯提升。

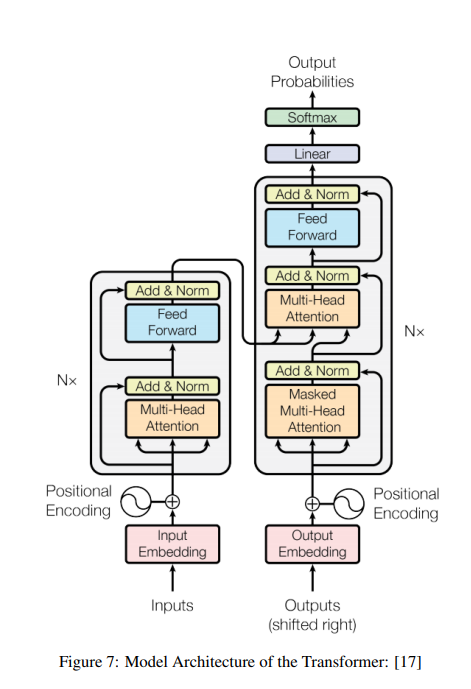
2017 年的 Transformer 則是更進一步的轉折。它幾乎不靠 RNN 的逐步遞迴,改以自我注意力(Self-Attention)為核心,句子裡的字可以同時互相比較、同時運算,平行度大幅提高值。這套架構後來成為 BERT、GPT 這類現代大語言模型的底層骨幹。
當今天使用者在 ChatGPT 輸入一句提示詞(Prompt)並按下送出,這個「文字旅程」就正式啟動了:
我們輸入的文字首先會被轉化為 Token,並在 Transformer 的多頭自我注意力機制中,同時與句子裡的其他字詞進行全局的比對與權重計算,精準捕捉複雜的前後文語意。
接著,模型會流暢地在後端進行高速的文字接龍,最終在我們的螢幕畫面上,一字字即時且流暢地輸出我們所看到的精準回覆。我們現在熟知的 AI 互動流程,很大程度上,就是站在這條演進路上長出來的成果。